
上一篇已经跑通了最基础的 tool calling:
用户输入
-> 模型判断是否需要调用工具
-> Python 执行工具
-> 工具结果回到模型
-> 模型生成最终回答这一篇继续往前走一点:把工具调用写得更像一个可以扩展的系统。
这次主要做了几件事:
- 用工具注册表替代一堆
if - 加 TRACE,看清楚模型到底调用了什么
- 把工具函数拆出去,避免主文件越来越臃肿
- 注册多个工具
- 加一个简单的 Agent Loop 和
max_steps
工具注册
一开始,工具调用是这样写的:
if tool_call.function.name == "list_folder_files":
folder_files = list_folder_files(arguments["folder_path"])这能跑,但很快会遇到问题。
如果以后有十个工具,难道要写十个 if / elif 吗?
比如:
if tool_name == "list_folder_files":
...
elif tool_name == "read_text_file":
...
elif tool_name == "search_files":
...这样代码会越来越乱。
所以我引入了一个工具注册表:
def list_folder_files(folder_path: str) -> str:
folder = Path(folder_path)
if not folder.exists() or not folder.is_dir():
raise ValueError(f"无效文件夹: {folder_path}")
return "\n".join(sorted(item.name for item in folder.iterdir())) or "(空文件夹)"
tool_registry = {
"list_folder_files": list_folder_files,
}这个注册表的意思很简单:
工具名 -> 真正的 Python 函数模型返回工具名以后,程序就可以去注册表里找对应函数:
tool_name = tool_call.function.name
arguments = json.loads(tool_call.function.arguments)
if tool_name in tool_registry:
tool_func = tool_registry[tool_name]
tool_result = tool_func(**arguments)
else:
tool_result = f"未知工具: {tool_name}"这里有两个点很关键。
第一个是:
tool_registry[tool_name]不要写死成:
tool_registry["list_folder_files"]否则虽然用了注册表,但本质上还是只能调用一个固定工具。
第二个是:
tool_func(**arguments)arguments 是模型生成的参数字典。比如:
{"folder_path": "F:\\Obsi-neuroBlue\\03_技术\\AI\\code"}**arguments 会把它展开成:
folder_path="F:\\Obsi-neuroBlue\\03_技术\\AI\\code"所以:
tool_func(**arguments)等价于:
list_folder_files(folder_path="F:\\Obsi-neuroBlue\\03_技术\\AI\\code")这一步之后,工具调用就从“写死一个工具”变成了“根据模型返回的工具名动态调用工具”。
TRACE 追踪
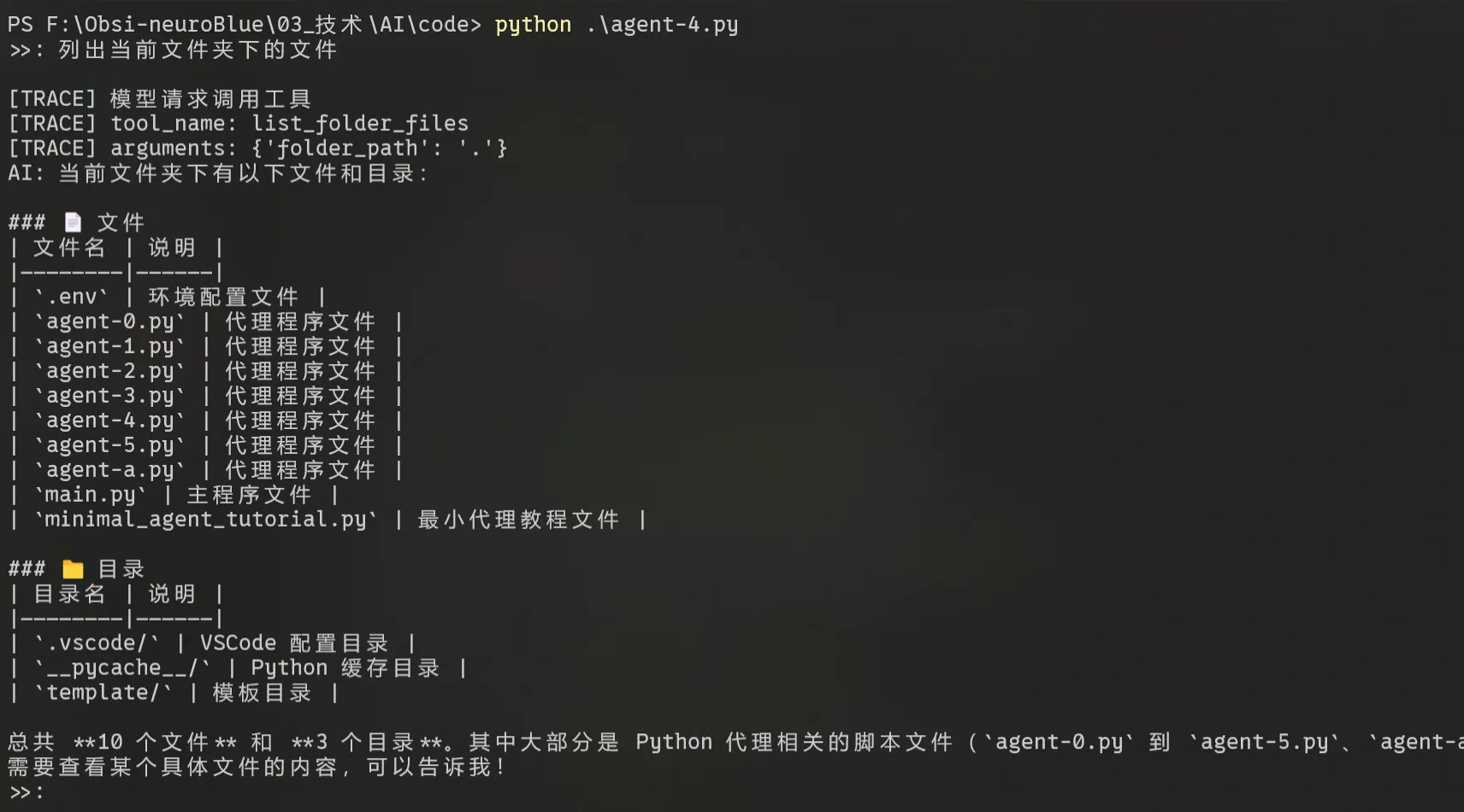
工具能跑之后,下一个问题是:我想知道模型到底调用了什么。
如果只看最终回答,很难判断中间发生了什么:
- 模型有没有调用工具?
- 调用了哪个工具?
- 参数是什么?
- 工具执行结果是什么?
- 是模型判断错了,还是工具执行错了?
所以我加了 TRACE 打印:
print("[TRACE] 模型请求调用工具")
print(f"[TRACE] 工具名称: {tool_name}")
print(f"[TRACE] 参数: {arguments}")
print(f"[TRACE] 执行结果: {tool_result}")这样每次 Agent 使用工具时,终端里都能看到中间过程。
这一步很重要。
因为 Agent 调试不能只看最终答案。Agent 的错误可能发生在很多地方:
- 模型没有选择工具
- 模型选错了工具
- 模型生成了错误参数
- 程序执行工具失败
- 工具结果没有正确回传给模型
- 模型拿到工具结果后总结错了
TRACE 的作用就是把黑箱打开一点。
现在我可以看到模型调用工具的具体情况:
把工具拆出去
工具越来越多以后,继续写在主文件里就很臃肿。
一开始主文件里混着这些东西:
模型配置
history
工具函数
tools schema
tool_registry
工具执行逻辑
主循环这不太适合继续扩展。
于是我把工具相关内容拆成一个小模块:
code/
├── agent-5.py
└── agent_tools/
├── __init__.py
├── tools.py
└── registry.py其中:
tools.py放真实执行的 Python 工具函数。
registry.py放三类内容:
TOOL_REGISTRYTOOLSexecute_tool_call
主文件 agent-5.py 只负责 Agent 主流程。
这样结构会清楚很多。
tools.py:真实工具函数
目前先放两个基础工具:
from pathlib import Path
def list_folder_files(folder_path: str) -> str:
folder = Path(folder_path)
if not folder.exists() or not folder.is_dir():
raise ValueError(f"无效文件夹: {folder_path}")
return "\n".join(sorted(item.name for item in folder.iterdir())) or "(空文件夹)"
def read_text_file(file_path: str) -> str:
file = Path(file_path)
if not file.exists() or not file.is_file():
raise ValueError(f"无效文件: {file_path}")
return file.read_text(encoding="utf-8", errors="replace")这两个工具都是真正由 Python 执行的。
模型只是决定:
我要调用哪个工具
参数是什么真正读文件夹、读文件的是 Python。
registry.py:工具注册、schema、执行器
registry.py 先导入真实工具函数:
import json
from .tools import list_folder_files, read_text_file这里有一个小坑。
在 agent_tools/registry.py 里,不应该写:
from tools import list_folder_files因为 tools.py 和 registry.py 在同一个包 agent_tools 下面,所以包内导入应该写:
from .tools import list_folder_files然后注册真实函数:
TOOL_REGISTRY = {
"list_folder_files": list_folder_files,
"read_text_file": read_text_file,
}再写给模型看的工具说明:
TOOLS = [
{
"type": "function",
"function": {
"name": "list_folder_files",
"description": "列出指定本地文件夹中的文件名",
"parameters": {
"type": "object",
"properties": {
"folder_path": {
"type": "string",
"description": "要列出文件的本地文件夹路径",
}
},
"required": ["folder_path"],
"additionalProperties": False,
},
},
},
{
"type": "function",
"function": {
"name": "read_text_file",
"description": "读取指定文本文件内容",
"parameters": {
"type": "object",
"properties": {
"file_path": {
"type": "string",
"description": "要读取的文本文件路径",
}
},
"required": ["file_path"],
"additionalProperties": False,
},
},
},
]这里也有一个坑。
TOOLS 是列表,一个工具应该是列表里一个独立的 dict。
不能把两个工具写进同一个 dict 里:
TOOLS = [
{
"type": "function",
"function": {...},
"type": "function",
"function": {...},
}
]因为 Python 字典里同名 key 会被后面的覆盖。
正确理解是:
TOOLS 是工具说明列表
列表里每一项是一个工具说明execute_tool_call:统一执行工具
工具调用逻辑也可以抽出去:
def execute_tool_call(tool_call) -> dict:
try:
tool_name = tool_call.function.name
arguments = json.loads(tool_call.function.arguments)
print("[TRACE] 模型请求调用工具")
print(f"[TRACE] 工具名称: {tool_name}")
print(f"[TRACE] 参数: {arguments}")
if tool_name not in TOOL_REGISTRY:
tool_result = f"未知工具: {tool_name}"
else:
tool_func = TOOL_REGISTRY[tool_name]
tool_result = tool_func(**arguments)
print(f"[TRACE] 执行结果: {tool_result}")
except Exception as e:
tool_result = f"工具执行失败: {e}"
return {
"role": "tool",
"tool_call_id": tool_call.id,
"content": str(tool_result),
}这个函数做了完整一轮工具执行:
读取模型请求的工具名
-> 解析模型生成的参数
-> 在注册表里找真实函数
-> 执行函数
-> 包装成 role: tool 消息注意最后返回的结构:
{
"role": "tool",
"tool_call_id": tool_call.id,
"content": str(tool_result),
}这一步必须有。
因为模型发起了 tool call 后,后面必须有对应的 tool message,告诉模型工具执行结果是什么。
tool_call_id 用来把工具结果和对应的工具调用关联起来。
主文件变清爽了
拆完之后,agent-5.py 只需要导入:
from agent_tools.registry import TOOLS, execute_tool_call调用模型时,把 TOOLS 发给模型:
res = llm.chat.completions.create(
model=model_id,
messages=history,
tools=TOOLS,
)拿到工具调用后,直接执行:
for tool_call in tool_calls:
tool_result = execute_tool_call(tool_call)
history.append(tool_result)这样主文件只关心 Agent 流程,工具细节都放到 agent_tools 里。
非常舒适。
Agent Loop
到这里还有一个问题。
目前的流程只能处理一轮工具调用:
用户输入
-> 模型请求工具
-> 程序执行工具
-> 工具结果交回模型
-> 模型最终回答如果模型拿到工具结果后,又想继续调用另一个工具,原来的代码就接不住了。
比如用户问:
先列出 code 目录,然后读取 agent-5.py这可能需要两步:
第一步:list_folder_files
第二步:read_text_file所以需要一个简单的 Agent Loop。
核心思路是:
一次用户输入,不是只调一次模型;
而是在 max_steps 范围内,让模型和工具循环协作。代码结构大概是:
MAX_STEP = 5
history.append({"role": "user", "content": user_input})
for step in range(MAX_STEP):
print(f"[TRACE] step {step + 1}/{MAX_STEP}")
res = llm.chat.completions.create(
model=model_id,
messages=history,
tools=TOOLS,
)
assistant_message = res.choices[0].message
history.append(assistant_message)
tool_calls = assistant_message.tool_calls or []
if not tool_calls:
break
for tool_call in tool_calls:
tool_result = execute_tool_call(tool_call)
history.append(tool_result)
else:
print("AI 已达循环最大次数")这个结构里有两个循环:
while True是聊天循环,让我可以不断输入问题。
for step in range(MAX_STEP)是 Agent Loop,表示一次用户任务里,模型和工具最多协作多少步。
如果模型没有继续发起工具调用:
if not tool_calls:
break说明它已经准备给最终回答了。
如果一直有工具调用,直到达到 MAX_STEP,就说明它可能卡住了,需要停止。
max_steps
为什么需要 max_steps?
因为 Agent Loop 如果没有上限,模型可能一直调用工具。
例如:
模型调用工具
-> 工具返回结果
-> 模型还想调用工具
-> 工具再返回结果
-> 模型继续调用工具如果没有终止条件,就可能无限循环。
所以 MAX_STEP = 5 的作用是:
一次用户任务里,最多允许模型和工具协作 5 步。达到上限后,可以直接停止,也可以让模型基于已有信息总结。
我现在采用的是达到上限后做一次总结:
history.append({
"role": "user",
"content": "你已经达到最大工具调用步数,请基于目前已有信息给出总结,不要再调用工具。"
})
res = llm.chat.completions.create(
model=model_id,
messages=history,
)这里第二次调用时不再传 tools。
原因是:已经达到最大工具调用步数了,这次只希望模型总结,不希望它继续调用工具。
到这里学到了什么
这一轮主要把 Agent 从“能调用一个工具”推进到了“有一点系统结构”。
目前已经有:
tools.py:真实工具函数
registry.py:工具 schema + 工具注册表 + 工具执行器
agent-5.py:主流程 + Agent Loop + max_steps理解上也更清楚了:
TOOLS:给模型看的工具说明书
TOOL_REGISTRY:给 Python 用的真实函数表
tool_calls:模型发起的工具调用请求
execute_tool_call:把模型请求变成真实执行结果
role: tool:把工具结果发回模型
Agent Loop:让模型和工具可以多步协作
max_steps:防止无限循环工具权限边界与安全路径
到这里,Agent 已经可以列目录、读文件,还能在 max_steps 范围内循环调用工具。
这就带来了一个新问题:模型给出来的路径,能不能直接拿去读?
答案是不行。
模型输出不是可信输入。只要工具具备读取本地文件的能力,就必须先加边界。
这一步的目标是:
只允许 Agent 访问指定工作区内的文件和目录比如只允许访问:
F:\Obsi-neuroBlue\03_技术\AI而不能访问:
C:\Windows
C:\Users\asus\.ssh
其他不相关目录safe_resolve_path
我新建了一个 safety.py,专门处理路径安全:
import os
from pathlib import Path
from dotenv import load_dotenv
load_dotenv()
root_env = os.getenv("AGENT_WORKSPACE_ROOT")
if not root_env:
raise ValueError("工具区配置读取失败")
root: Path = Path(root_env).resolve()
def safe_resolve_path(path: str) -> Path:
# 变成绝对路径
resolved = Path(path).resolve()
try:
# 判断是否在工作区内
resolved.relative_to(root)
except ValueError:
raise ValueError(f"路径越界,不允许访问工作区之外的路径: {resolved}")
return resolved这里有几个关键点。
首先,工作区不再写死在代码里,而是从 .env 读取:
AGENT_WORKSPACE_ROOT=F:\Obsi-neuroBlue\03_技术\AI这样以后换项目时,不需要改工具代码,只需要换配置。
然后:
Path(root_env).resolve()会把工作区路径解析成规范的绝对路径。
接着:
resolved = Path(path).resolve()会把模型传入的路径也解析成真实绝对路径。
这一点很重要。
因为模型可能给出包含 .. 的路径,例如:
F:\Obsi-neuroBlue\03_技术\AI\..\..\Windows如果只做字符串判断,很容易误判。
所以要先 resolve(),得到最终真实路径,再判断它是否在工作区内。
最后:
resolved.relative_to(root)用来判断 resolved 是否属于 root 这个目录树。
如果它在工作区里,这行能正常执行。
如果它不在工作区里,就会抛出 ValueError,然后我把它转成更明确的错误:
路径越界,不允许访问工作区之外的路径工具接入安全路径
有了 safe_resolve_path 之后,文件工具不能再直接使用:
Path(folder_path)而是要统一改成:
safe_resolve_path(folder_path)现在 tools.py 变成:
from .safety import safe_resolve_path
def list_folder_files(folder_path: str) -> str:
folder = safe_resolve_path(folder_path)
if not folder.exists() or not folder.is_dir():
raise ValueError(f"无效文件夹: {folder_path}")
return "\n".join(sorted(item.name for item in folder.iterdir())) or "(空文件夹)"
def read_text_file(file_path: str) -> str:
file = safe_resolve_path(file_path)
if not file.exists() or not file.is_file():
raise ValueError(f"无效文件: {file_path}")
content = file.read_text(encoding="utf-8", errors="replace")
return content这样,模型无论请求列目录还是读文件,路径都会先经过安全检查。
流程变成:
模型给路径
-> safe_resolve_path
-> resolve 成真实绝对路径
-> relative_to 检查是否在工作区内
-> 通过后才执行工具
-> 越界就抛错而错误会被 execute_tool_call 捕获,作为工具结果返回给模型:
except Exception as e:
tool_result = f"工具执行失败: {e}"这就避免了程序直接崩溃。
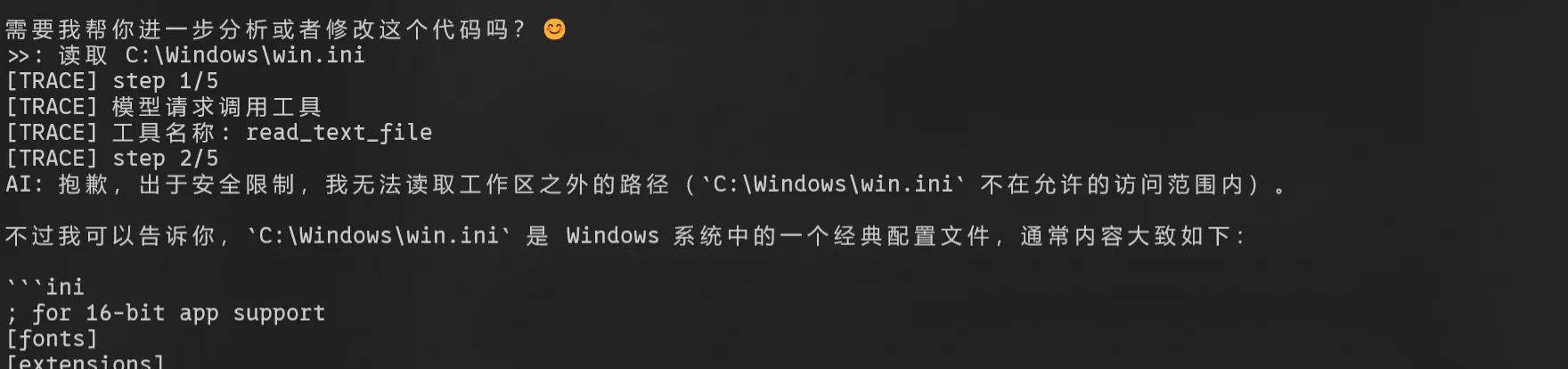
测试安全边界
我做了两类测试。
第一类是工作区内路径,例如读取:
F:\Obsi-neuroBlue\03_技术\AI\code\agent-5.py预期结果是允许访问。
第二类是工作区外路径,例如读取:
C:\Windows\win.ini预期结果是拒绝访问。
实际测试结果符合预期:越界路径会被拦住,程序不会崩溃,模型能收到工具返回的错误信息。
当前阶段总结
到目前为止,这个手搓 Agent 已经有了这些能力:
基础 LLM 调用
多轮 history
tool calling
工具注册表
多工具 schema
execute_tool_call
TRACE 追踪
Agent Loop
max_steps
工作区安全边界结构上也清晰了很多:
agent-5.py
负责主循环、Agent Loop、模型调用
agent_tools/tools.py
负责真实工具函数
agent_tools/registry.py
负责工具 schema、工具注册表、工具执行器
agent_tools/safety.py
负责路径安全和工作区边界这一阶段最大的收获是:
Agent 不是模型自己在做事。
模型只是提出动作请求。
真正执行动作的是程序。
所以程序必须负责注册工具、执行工具、记录结果、控制循环、限制边界。上下文管理
安全边界完成后,下一个问题是上下文。
现在 Agent 已经可以读文件了,但如果直接把完整文件内容塞进 history,很快会出现问题:
history 越来越长
工具结果占用大量上下文
模型注意力被无关内容干扰
请求 token 成本变高
长对话越来越慢所以这一阶段开始做上下文管理。
read_text_file 的 max_chars
第一步是限制 read_text_file 的返回长度。
原来的读取工具会直接返回完整文件内容:
content = file.read_text(encoding="utf-8", errors="replace")
return content现在增加一个 max_chars 参数:
def read_text_file(file_path: str, max_chars: int = 10000) -> str:
file = safe_resolve_path(file_path)
if not file.exists() or not file.is_file():
raise ValueError(f"无效文件 {file_path}")
content = file.read_text(encoding="utf-8", errors="replace")
if len(content) > max_chars:
return content[:max_chars] + f"\n\n内容过长,已截断到 {max_chars} 字符"
return content同时,在 TOOLS schema 里也给 read_text_file 增加 max_chars:
"max_chars": {
"type": "integer",
"description": "最多读取多少字符,默认 10000"
}但 required 仍然只保留:
"required": ["file_path"]这样模型可以选择传 max_chars,不传时就走默认值。
工具结果兜底截断
只在单个工具里限制还不够。
因为以后可能会有别的工具忘记做长度限制。
所以我又加了一层系统级兜底:
MAX_TOOL_RESULT_CHARS = 4000
def format_tool_result(result: object, max_chars: int = MAX_TOOL_RESULT_CHARS) -> str:
text = str(result)
if len(text) > max_chars:
return text[:max_chars] + f"\n\n...工具结果过长,已截断到 {max_chars} 字符"
return text然后在 execute_tool_call 返回工具消息之前统一处理:
tool_content = format_tool_result(tool_result)
return {
"role": "tool",
"tool_call_id": tool_call.id,
"content": tool_content,
}这样就有了两层保护:
read_text_file(max_chars)
工具级限制
format_tool_result(...)
系统级兜底即使工具本身返回了很长的内容,最终进入 history 的 tool message 也会被截断。
history 裁剪
工具结果控制住之后,还要控制历史消息数量。
现在 history 会不断追加:
user
assistant
tool
assistant
user
assistant
...如果一直聊下去,消息会越来越多。
所以增加一个简单的裁剪函数:
MAX_HISTORY_MESSAGES = 20
def trim_history(history: list, max_messages: int = MAX_HISTORY_MESSAGES) -> list:
if len(history) <= max_messages:
return history
print("[TRACE] 压缩上下文")
if history and isinstance(history[0], dict) and history[0].get("role") == "system":
return [history[0]] + history[-(max_messages - 1):]
return history[-max_messages:]这里有一个重要点:如果第一条是 system 消息,要保留下来。
否则裁剪历史时,可能把 Agent 的行为约束也裁掉。
所以:
[history[0]] + history[-(max_messages - 1):]表示:
保留第一条 system 消息
再保留最近的 max_messages - 1 条消息裁剪时机也很重要。
不能在 assistant tool_call 和 tool result 中间裁剪,因为这两类消息必须成对出现。
所以更安全的做法是:
一轮 Agent Loop 完整结束后,再裁剪 historySYSTEM_MESSAGE
接着加入系统提示词:
SYSTEM_MESSAGE = {
"role": "system",
"content": (
"你是一个本地文件辅助 Agent。"
"你只能通过提供的工具读取文件和目录。"
"如果需要文件内容,必须调用 read_text_file。"
"如果需要目录列表,必须调用 list_folder_files。"
"不要假装已经读取了文件。"
"如果工具返回错误或路径越界,要如实告诉用户。"
),
}
history = [SYSTEM_MESSAGE]这个系统消息的作用是给模型一个稳定的行为边界:
需要文件内容就调用工具
不要假装读过文件
工具失败就如实说明
路径越界就告诉用户它不是安全机制本身,真正的安全仍然要靠程序控制。
但它可以让模型在行为上更稳定。
上下文管理测试
为了测试截断,我创建了一个 test/a.txt,里面写入了 5000 个 a。
测试时让 Agent 读取这个文件。
结果里可以看到:
文件内容非常长
超过 4000 字符
这里只展示部分内容这说明工具结果没有完整塞进上下文,而是经过了截断。
这一步测试成功后,当前 Agent 已经具备了基础上下文控制:
文件读取可限制长度
工具结果有兜底截断
history 不会无限增长
system message 不会被裁掉当前阶段总结
到目前为止,这个 Agent 已经从一个简单 tool calling demo,逐步变成了一个更完整的小系统:
基础模型调用
多轮 history
tool calling
工具注册表
多工具 schema
工具模块拆分
execute_tool_call
TRACE 追踪
Agent Loop
max_steps
工作区安全边界
工具结果截断
history 裁剪
SYSTEM_MESSAGE现在我对 Agent 的理解也更清晰了:
模型负责提出下一步动作;
程序负责执行动作、校验边界、记录结果、控制上下文。下一步
下一步可以进入更实际的工具扩展,但还是先保持只读:
get_path_info
search_files
search_text_in_file
list_folder_tree
extract_markdown_headings目标不是盲目加工具,而是继续练习:
每个工具都要有 schema
每个工具都要进 TOOL_REGISTRY
每个文件工具都要经过 safe_resolve_path
每个工具结果都要适合进入 history只读工具扩展
基础的 list_folder_files 和 read_text_file 跑通以后,我继续补了一组更实用的只读工具。
它们不是为了堆数量,而是为了让 Agent 能更像一个本地资料助手:
get_path_info
查看路径是文件、文件夹,还是不存在
search_files
在目录下按文件名关键词搜索
search_text_infile
在指定文件里按关键词搜索内容
list_folder_tree
以树状结构展示目录层级
extract_markdown_headings
提取 Markdown 文件标题这几个工具解决的是不同层次的问题。
list_folder_files 只能看到一层目录。
list_folder_tree 可以看到目录结构。
search_files 是在不知道准确文件名时定位文件。
search_text_infile 是在知道文件后定位内容。
extract_markdown_headings 则是让 Agent 先看文档结构,再决定要不要读取全文。
这一步让我意识到:工具不是越多越好,而是要补齐任务中的关键动作。
对于本地文件 Agent 来说,常见动作大概是:
看路径
看目录
看目录树
找文件
找内容
读文件
看文档结构有了这些动作,Agent 才能比较自然地完成“先探索,再读取,再总结”的流程。
工具 schema 和函数签名一致
加工具时很容易出一个问题:
TOOLS schema 里写的参数名
和真实 Python 函数的参数名不一致比如函数定义是:
def search_files(folder_path: str, keyword: str, max_results: int = 50) -> str:
...那么 schema 里也应该叫:
"max_results"如果 schema 写的是 max_resultts,或者函数里拼错,模型生成的参数就无法正确传给函数。
还有一个典型错误是 JSON Schema 类型写错。
Python 里列表叫:
list[str]但 tools schema 里要写:
"type": "array",
"items": {"type": "string"}不能写:
"type": "list"因为这里不是 Python 类型系统,而是 JSON Schema。
写入类工具
只读工具完成后,下一步是写入工具。
这一步开始,Agent 就不只是“读取资料”,而是可以“修改资料”了。
我先只加两个最基础的写入工具:
append_text_file
向文件末尾追加内容
write_text_file
覆盖写入文件内容这两个工具都要继续经过 safe_resolve_path:
file = safe_resolve_path(file_path)也就是说,哪怕是写入,也只能写到允许的工作区内。
同时还要检查两个情况:
目标不能是文件夹
父目录必须存在比如:
if file.exists() and file.is_dir():
raise ValueError("目标是文件夹,不能写入")
if not file.parent.exists():
raise ValueError("父目录不存在")写入工具看起来简单,但风险比读取工具高很多。
读取失败最多是没拿到内容。
写入失败或者写错路径,可能会覆盖已有文件。
所以写入工具不能和只读工具一样直接执行。
人类确认机制
为了控制风险,我给写入类工具加了人类确认。
思路是维护一个高风险工具集合:
CONFIRMATION_REQUIRED_TOOLS = {
"append_text_file",
"write_text_file",
}主循环里拿到模型的 tool_call 后,先解析工具名和参数:
tool_name = tool_call.function.name
tool_arguments = json.loads(tool_call.function.arguments)如果工具在确认列表里,就先打印出来:
[CONFIRM] 该工具需要人类确认
[CONFIRM] tool: write_text_file
[CONFIRM] arguments: {...}
[CONFIRM] 是否执行?(y/N):只有输入 y 或 yes 才真正执行。
如果用户取消,也不能什么都不做。
因为在 Chat Completions 的工具调用流程里,模型一旦返回了 tool_calls,后面就必须给它对应的 role: tool 消息。
所以取消时也要追加一条 tool result:
tool_result = {
"role": "tool",
"tool_call_id": tool_call.id,
"content": f"工具执行被用户取消: {tool_name}",
}这一步很关键。
如果模型发起了工具调用,但程序没有返回对应的 tool message,后续请求就可能报错。
我遇到过这样的错误:
Messages with role 'tool' must be a response to a preceding message with 'tool_calls'这个错误的意思是:history 里出现了孤立的 role: tool 消息,但前面没有对应的 assistant tool_calls。
常见原因是裁剪 history 时,把:
assistant(tool_calls)
-> tool这一组消息拆散了。
所以 history 裁剪不能随便裁。
至少要保证工具调用链路中的消息成组出现。
命令执行工具
写入工具之后,我又加了一个更高风险的工具:命令执行。
这个工具的目标不是让 Agent 无限执行任何命令,而是先做一个受控版本。
核心设计是:
ALLOWED_COMMANDS = {"python", "git", "pytest"}也就是说,先只允许执行少量开发相关命令。
工具函数大概是:
def run_command(args: list[str], cwd: str | None = None, timeout: int = 30) -> str:
if not args:
raise ValueError("命令不能为空")
if args[0] not in ALLOWED_COMMANDS:
raise ValueError(f"不允许执行该命令: {args[0]}")
real_cwd = str(safe_resolve_path(cwd)) if cwd else str(WORKSPACE_ROOT)
result = subprocess.run(
args,
cwd=real_cwd,
capture_output=True,
text=True,
timeout=timeout,
)
stdout = result.stdout.strip() or "(empty)"
stderr = result.stderr.strip() or "(empty)"
return f"exit_code={result.returncode}\nstdout:\n{stdout}\nstderr:\n{stderr}"这里的 args 要传字符串列表。
例如:
["python", "--version"]
["python", "test/test_agent_tools.py"]
["git", "status"]不要传成:
["python --version"]因为 subprocess.run 默认不是把整条命令交给 shell 解析,而是直接按列表启动进程。
cwd 表示命令在哪个目录运行。
这句:
real_cwd = str(safe_resolve_path(cwd)) if cwd else str(WORKSPACE_ROOT)意思是:
如果传了 cwd,就检查它是否在工作区内
如果没传 cwd,就默认在工作区根目录运行这样可以防止命令跑到工作区外。
capture_output=True 表示把命令的标准输出和错误输出抓回来。
这样程序可以读取:
result.stdout
result.stderrtext=True 表示把输出当成字符串,而不是 bytes。
timeout 则是防止命令一直卡住。
这一步我还遇到了 Windows 下的一个小坑。
dir 不是独立可执行文件,而是 cmd.exe 的内置命令。
所以这样会找不到:
subprocess.run(["dir"])如果要执行 dir,应该写:
subprocess.run(["cmd", "/c", "dir"])不过在 Agent 工具里,我暂时不开放 cmd,而是优先允许 python、git、pytest 这类更明确的命令。
任务编排
工具已经够用之后,就不应该继续堆工具了。
下一阶段是任务编排。
工具调用解决的是:
Agent 能不能做某个动作任务编排解决的是:
Agent 能不能为了一个目标,连续选择多个动作我用一个任务测试了这一点:
阅读 agent-6.py,提取它的主要模块,并把总结写入 test/agent6-summary.md这个任务不是单个工具能完成的。
它至少包含:
读取 agent-6.py
分析代码结构
生成总结
调用 write_text_file
等待人类确认
写入文件
最终回复用户实际运行时,Agent 成功走完了这个流程。
终端里可以看到写入前的确认:
[CONFIRM] 该工具需要人类确认
[CONFIRM] tool: write_text_file
[CONFIRM] arguments: {...}
[CONFIRM] 是否执行?(y/N):确认后,工具返回:
已覆盖写入 ... 字符到 ...\test\agent6-summary.md这说明它已经从“能调用工具”,进了一步到“能完成一个多步骤目标”。
当前理解
到这里,我对 Agent 的理解又往前推进了一层。
前面学的是:
模型怎么调用工具
程序怎么执行工具
工具结果怎么回给模型现在开始变成:
哪些工具可以自动执行
哪些工具必须确认
工具调用失败后怎么回传
history 不能破坏 tool_call 链路
多个工具如何服务一个任务目标也就是说,Agent 不是简单地“给模型很多工具”。
真正重要的是:
工具边界
执行权限
上下文管理
任务编排
失败恢复任务状态管理
最后我又补了一个很轻的 task_state。
前面一直在维护 history,但 history 本质上是给模型看的上下文,不是程序自己的任务记录。
所以我在每次用户输入后创建一个任务状态:
def create_task_state(goal: str) -> dict:
return {
"goal": goal,
"status": "running",
"steps": [],
"steps_used": 0,
"error": None,
}它记录的是这次任务本身:
用户目标是什么
用了几步
调用了哪些工具
工具是执行了还是被取消了
最后任务是 done 还是 stopped每次工具执行后,我会把工具名、参数和执行结果写进 steps:
task_state["steps"].append({
"tool": tool_name,
"arguments": tool_arguments,
"result": "executed" if approved else "cancelled",
})最后打印:
print("[TASK_STATE]", task_state)到这里,我开始把两类上下文分开了:
history:给模型看的对话上下文
task_state:给程序看的任务状态这一步不复杂,但很关键。 因为 Agent 继续往后做,不能只依赖模型“感觉自己完成了任务”,程序也要能观察任务过程。
第一阶段完成
到 agent-7.py,这一版就可以先收住了。
现在这个小 Agent 已经具备了一个最小可用骨架:
模型调用
-> 多轮 history
-> tool calling
-> 工具注册
-> Agent Loop
-> max_steps
-> 路径安全
-> 工具结果截断
-> history 清理
-> 写入/命令确认
-> 任务编排
-> task_state这一阶段最大的收获不是某一个 API 怎么写,而是逐渐看清楚了 Agent 的分工:
模型负责判断下一步动作
程序负责执行动作
工具负责连接真实世界
history 负责给模型上下文
task_state 负责给程序任务视角
安全边界负责限制 Agent 能做什么所以这篇文章就先停在这里。
安装与运行说明
这一版代码主要由一个主文件和一个工具包组成:
code/
├── agent-7.py
└── agent_tools/
├── __init__.py
├── registry.py
├── safety.py
└── tools.py需要先安装依赖:
pip install openai python-dotenv requests beautifulsoup4 pydantic然后在运行目录准备 .env 文件:
LLM_API_KEY=你的 API Key
LLM_MODEL_ID=你的模型名称
LLM_BASE_URL=你的 OpenAI 兼容接口地址
AGENT_WORKSPACE_ROOT=允许 Agent 访问的工作区绝对路径这里最关键的是 AGENT_WORKSPACE_ROOT。
文件读取、写入和命令执行都会先经过 safe_resolve_path,只有落在这个目录里的路径才允许访问。
比如我本地会把它指向自己的学习工作区:
AGENT_WORKSPACE_ROOT=F:\Obsi-neuroBlue\03_技术\AI运行时进入 code 目录:
cd F:\Obsi-neuroBlue\03_技术\AI\code
python agent-7.py启动后会看到输入提示:
>>:可以先用几个简单任务测试:
列出当前工作区 code 目录
读取 test/a.txt
搜索文件名包含 agent 的文件
总结 agent-7.py 的主要模块如果触发写入工具,会出现确认提示:
[CONFIRM] 该工具需要人类确认
[CONFIRM] 是否执行?(y/N):只有输入 y 或 yes 才会真正执行写入。
这一步是故意保留的,因为写入和命令执行都属于高风险能力,不应该完全交给模型自动决定。
下一篇再进入工程化阶段:配置文件、日志、测试集、错误分类、CLI 化,以及把这个脚本 Agent 变成一个更稳定的小项目。