
记一次手动收入预测
这是一个基于 python 的基于收入预测支出的简单程序。
1 | # 每月收入 |
一组散点数据,为预测模型提供输入。
绘制散点图看一下效果
1 | def show(): |
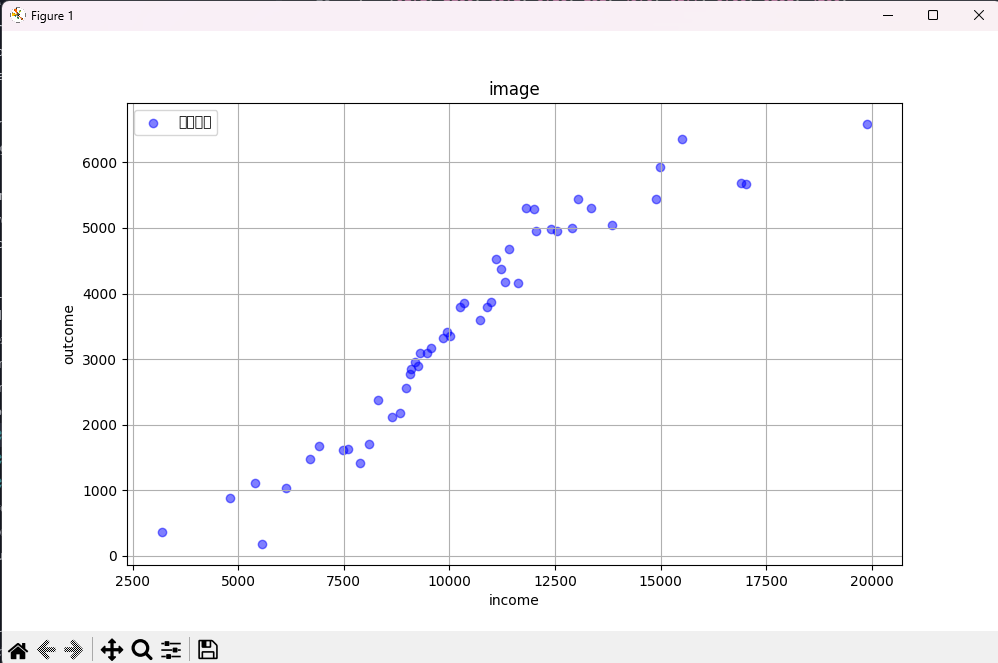
可以看到,x,y 成线性相关
同时,利用 numpy 计算一下 x,y 的相关系数
print(np.corrcoef(x, y))
==》
1 | [[1. 0.94862936] |
相关系数 0.94862936 (接近 -1 或者 1 为强相关)
KNN算法预测
- 使用 heapq.nsmallest 找出k个最接近的收入值
- 计算这k个收入值对应的支出的平均值作为预测结果
大白话:就是给一个 X_ 收入,找出距离 X_ 最近的 K 个数 x,取这 K 个数对应 y 值的平均值作为 X_ 的 Y_ 的预测结果。
1 | sample_data = {key:value for key,value in zip(x,y)} |
运行效果
1 | 月收入: 1800,月支出: 712.6 |
可以看到,预测结果简直一坨
原因是这种根据距离求平均值的算法误差太大?
楞猜法预测
由于已知该数据呈一定的线性关系,所以可以根据直线 y=ax + b 去拟合
而参数 a,b 就是我们需要找到的值
问题转化如何找到 a,b,使拟合效果最好
于是定义损失函数求均方误差,就是高中学的方差的平均值
先定义一个很大的 current_loss,然后随机取 a,b,带入 X_ ,将求出的平均方差与 current_loss 比较,若平均方差较小,则更新 current_loss ,继续随机取 a,b ,直到找到使 current_loss 最小的 a,b ,即为所求参数。
1 | def get_loss(X_,Y_,a_,b_): |
==》
1 | 最小损失为:0.00, 对应的斜率为:0.42, 对应的截距为:-9.39 |
效果一般
增大随机模拟次数,加上进度条动态展示模拟进度
1 | min_loss, a, b = 1e12, 0, 0 |
1 | 训练进度: 100%|███████████████████████████| 100000000/100000000 [25:49<00:00, 64552.47it/s] |
可见,随着模拟次数的增加,current_loss 越小,a,b 的取值越准确
最后,我们根据这个 a,b 值,来重新画出回归线
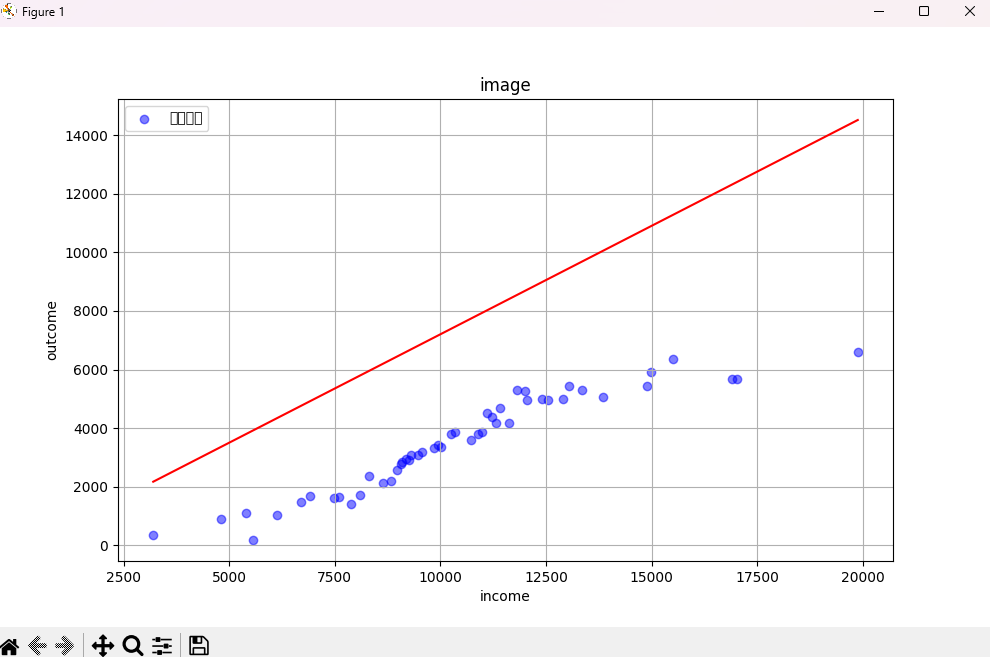
仍然拟合地一坨,后续再进行优化。
后记:初探人工智障,菜鸡一枚。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Comments




